
Sisältö
Lähde: Kran77 / Dreamstime.com
Ottaa mukaan:
Syvän oppimisen mallit opettavat tietokoneita ajattelemaan yksinään, antaen erittäin hauskoja ja mielenkiintoisia tuloksia.
Syväoppimista sovelletaan yhä useampaan osa-alueeseen ja toimialaan. Kuljettajattomista autoista Go-pelien pelaamiseen ja kuvien musiikin tuottamiseen on päivittäin uusia syvän oppimisen malleja. Täällä käydään läpi useita suosittuja syvän oppimisen malleja. Tutkijat ja kehittäjät ottavat nämä mallit ja muuttavat niitä uudella ja luovalla tavalla. Toivomme, että tämä esittely voi inspiroida sinua näkemään, mikä on mahdollista. (Lisätietoja tekoälyn edistymisestä on artikkelissa, pystyvätkö tietokoneet jäljittelemään ihmisen aivoja?)
Neuraali tyyli
Et voi parantaa ohjelmointitaitojasi, kun kukaan ei välitä ohjelmiston laadusta.
Neuraali tarinakerros

Neural Storyteller on malli, joka kuvan saaneessa voi tuottaa romanssitarinan kuvasta. Se on hauska lelu, ja silti voit kuvitella tulevaisuuden ja nähdä suunnan, johon kaikki nämä tekoälyn mallit liikkuvat.

Yllä oleva toiminto on "tyylivaihto", jonka avulla malli voi siirtää vakiokuvatekstit tarinoiden tyyliin romaaneista. Tyylin muuttaminen on inspiroinut "Taiteellisen tyylin neuraalgoritmi".
data
Tässä mallissa on kaksi tärkeintä tietolähdettä. MSCOCO on Microsoftin tietojoukko, joka sisältää noin 300 000 kuvaa, jokaisessa kuvassa viisi kuvatekstiä. MSCOCO on ainoa käytetty valvottu tieto, mikä tarkoittaa, että se on ainoa tieto, johon ihmisten piti mennä sisään ja kirjoittaa selkeästi kuvatekstit jokaiselle kuvalle.
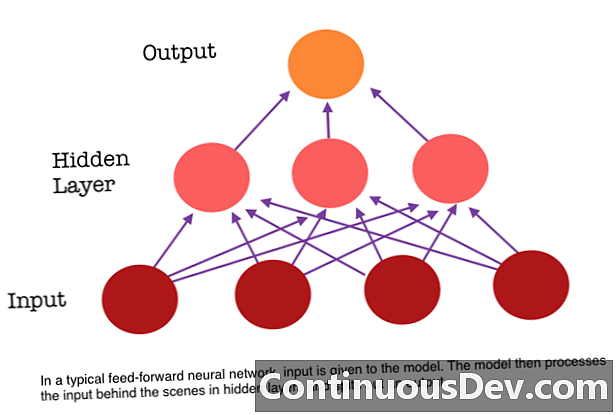
Yksi eteenpäin suuntautuvan hermoverkon suurimmista rajoituksista on, että siinä ei ole muistia. Jokainen ennustus on riippumaton aiemmista laskelmista, ikään kuin se olisi ensimmäinen ja ainoa ennuste, jonka verkko on koskaan tehnyt. Mutta monien tehtävien, kuten lauseen tai kappaleen kääntämisen, syöttöjen tulisi koostua peräkkäisistä ja yhdessä liittyvistä tiedoista. Esimerkiksi, olisi vaikeaa ymmärtää yhtä sanaa lauseessa ilman ympäröivien sanojen tarjoamaa huomiota.
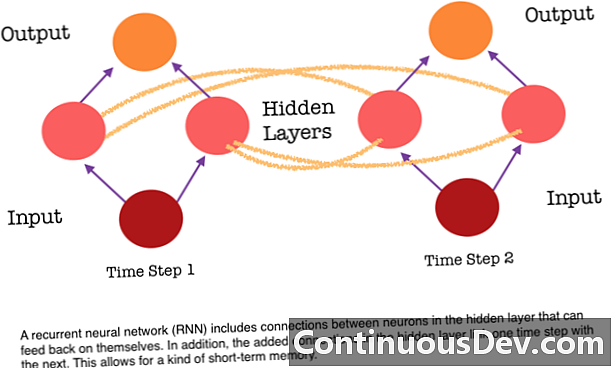
RNN: t ovat erilaisia, koska ne lisäävät toisen joukon yhteyksiä neuronien välille. Nämä linkit sallivat piilotetun kerroksen neuronien aktivoitumisen palautua takaisin itsensä sekvenssin seuraavassa vaiheessa. Toisin sanoen, jokainen vaihe piilotettu kerros saa sekä aktivoinnin sen alla olevalta kerrokselta että myös sekvenssin edelliseltä vaiheelta. Tämä rakenne antaa olennaisesti toistuvat hermoverkkojen muistit. Joten esineiden havaitsemista varten RNN voi vedota aiempiin koirien luokituksiinsa auttaakseen määrittämään, onko nykyinen kuva koira.
Char-RNN TED
Tämän joustavan piilotetun kerroksen rakenteen ansiosta RNN: t ovat erittäin hyviä merkkitason kielimalleille. Alun perin Andrej Karpathyn luoma Char RNN on malli, joka ottaa yhden tiedoston syötteenä ja kouluttaa RNN: n oppimaan ennustamaan seuraavaa merkkiä sarjassa. RNN voi luoda merkki merkiltä, joka näyttää alkuperäiseltä harjoitustiedolta. Demo on koulutettu erilaisten TED-puheiden kopioiden avulla. Syötä malli yhdelle tai useammalle avainsanalle ja se tuottaa osan avainsanoista TED-keskustelun ääni / tyyli.
johtopäätös
Nämä mallit osoittavat uusia läpimurtoja koneintelyssä, jotka ovat mahdollisia syvän oppimisen takia. Syvä oppiminen osoittaa, että voimme ratkaista ongelmat, joita emme koskaan pystyneet ratkaisemaan aikaisemmin, ja emme ole vielä saavuttaneet tuota tasangoa. Odotamme näkevänsä useita mielenkiintoisempia asioita, kuten kuljettajattomat autot seuraavien parin vuoden aikana syvän oppimisen innovaatioiden tuloksena.